



Khoa Sư phạm
Trường Đại học Hà Tĩnh
Phan Nguyễn Hoàng Long – một kỹ sư Việt 25 tuổi là đồng tác giả chính của bài báo "A benchmark of expert-level academic questions to assess AI capabilities" (tạm dịch: Một bộ câu hỏi học thuật cấp chuyên gia để đánh giá khả năng của trí tuệ nhân tạo) được công bố ngày 28/01 trên tạp chí Nature. Việc công bố trên tạp chí Nature – một trong những tạp chí khoa học uy tín hàng đầu thế giới đã đánh cột mốc quan trọng trong sự nghiệp học thuật của một nhà khoa học.

Kỹ sư Phan Nguyễn Hoàng Long làm việc tại Center for AI Safety (CAIS)
Bài báo trình bày kết quả nghiên cứu của dự án Humanity’s Last Exam (HLE) – bộ chuẩn đánh giá năng lực kiến thức và suy luận ở trình độ chuyên gia của các mô hình ngôn ngữ lớn (LLM) như ChatGPT, Gemini, Grok,... HLE gồm 2.500 câu hỏi chuyên sâu thuộc 100 lĩnh vực như toán học, khoa học tự nhiên và xã hội..., được xây dựng với sự tham gia của hơn 1.000 giáo sư, chuyên gia đến từ 500 trường đại học, tổ chức nghiên cứu hàng đầu thế giới như Stanford, Harvard, Princeton, MIT, Oxford...
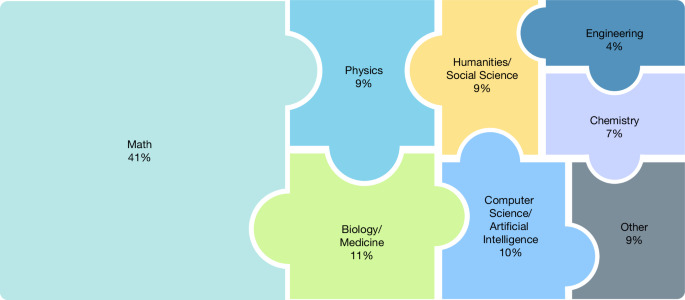
Phân bố các câu hỏi HLE theo từng lĩnh vực
Để thu hút các câu hỏi có chất lượng cao, nhóm nghiên cứu đã thiết lập quỹ giải thưởng trị giá 500.000 USD, với giải thưởng 5.000 USD cho mỗi câu hỏi trong top 50 và giá trị giải thưởng cho 500 câu hỏi tiếp theo sẽ do ban tổ chức quyết định. Với cơ cấu khuyến khích này, kết hợp với cơ hội đồng tác giả bài báo cho bất kỳ ai có câu hỏi được chấp nhận trên HLE, đã thu hút sự tham gia của các chuyên gia có trình độ, đặc biệt là những người có bằng cấp cao hoặc kinh nghiệm nổi bật trong lĩnh vực AI.
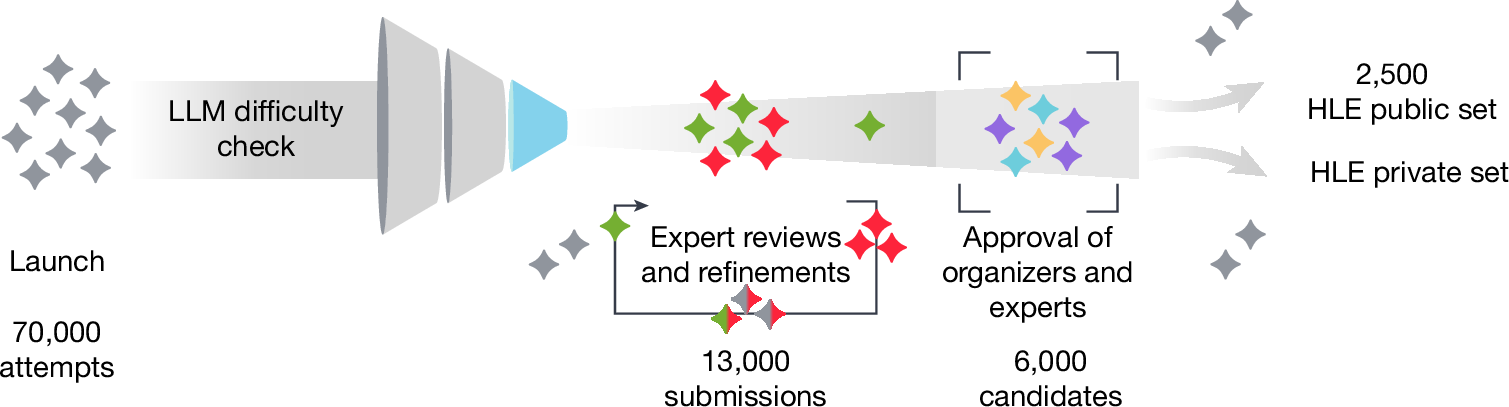
Quy trình tạo ra bộ dữ liệu HLE
HLE hiện được sử dụng như một thước đo quan trọng trong quá trình phát triển và công bố các mô hình AI của OpenAI, DeepMind và xAI; trong đó, xAI đã áp dụng HLE khi phát triển Grok 4 vào tháng 7/2025. Tờ New York Times từng nhận định HLE khó đến mức "khi AI vượt qua, chúng ta phải coi chừng". Thực tế, nó được sử dụng như một trong những thước đo quan trọng nhất của các công ty như DeepMind, OpenAI, xAI khi ra mắt các mô hình AI. Hồi tháng 7/2025, HLE được xAI sử dụng để phát triển Grok 4. Elon Musk đã đánh giá bài thi này "cực kỳ khó" trong buổi livestream ra mắt.

Các ví dụ câu hỏi từ bộ dữ liệu HLE
Theo Hoàng Long, HLE không chỉ là công cụ đánh giá kỹ thuật mà còn cung cấp cơ sở tham chiếu cho các nhà hoạch định chính sách trong việc nhận diện rủi ro và xây dựng khung quản lý phù hợp, góp phần định hướng sự phát triển AI theo hướng an toàn và có trách nhiệm.
Tin mới
- Dạy học STEM cho học sinh Tiểu học - từ ý tưởng đến thực tế - 24/03/2026 14:59
- Khoa Sư phạm đẩy mạnh hoạt động tình nguyện “đại sứ ngôn ngữ”, thắt chặt tình hữu nghị Việt – Lào - 21/03/2026 14:37
- Cảm nhận về hai tuần được vinh dự về thực tập dưới mái trường TH, THCS & THPT Đại học Hà Tĩnh - 16/03/2026 12:47
- Vũ đạo “trend” và những vấn đề đặt ra trong giáo dục nghệ thuật cho trẻ - 15/03/2026 08:03
- Tác phẩm: Bên nhau ngày hội (chào mừng bầu cử Quốc hội và Hội đồng Nhân dân) - 12/03/2026 03:28
Các tin khác
- Phương pháp dạy học tích cực sau kỳ nghỉ Tết - 26/02/2026 17:16
- Trò chơi dân gian - Mạch nguồn nuôi dưỡng tâm hồn và trí tuệ trẻ thơ - 16/02/2026 09:04
- Những thay đổi "bước ngoặt" trong quy chế tuyển sinh đại học 2026: Thí sinh cần biết gì? - 15/02/2026 13:06
- Chi bộ Khoa Sư phạm nghiêm túc tham dự Hội nghị toàn quốc nghiên cứu, học tập, quán triệt Nghị quyết Đại hội XIV - 14/02/2026 07:02
- Vai trò của Chi bộ trong công tác phát triển Đảng viên là sinh viên - 01/02/2026 23:24